
| Blog | |
| Releases |
Page:
0 1 2 3 4 ... 5 ... 10 ... 15 ... 20 ... 25 ... 30 ... 35 ... 40 ... 45 ... 50 ... 55 ... 60 ... 65 ... 70 ... 75 ... 80 ... 85 ... 90 ... 95 ... 100 ... 105 ... 110
| Scribe 3.2 | |
|---|---|
|
Date: 11/10/2023 Tags: scribe | So I've released Scribe v3.2, not so much because I finished testing all the things, but because I need some usability feedback. And it's been too long since a release. Somewhat disappointingly the size of the Linux build seems to have grown alarmingly without any good reason: 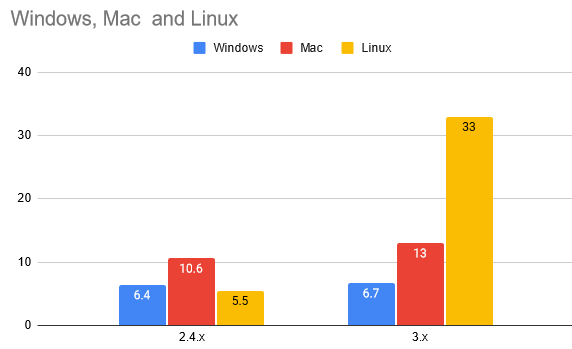 Yeah that's not a typo. And I have looked into it, all the basics like "is the binary built with -Os?" and "is the binary striped?" etc. And nothing obvious stands out. I would love a second opinion on this... just to sanity check the Linux build and see if I'm doing anything dumb? |
| (1) Comment | Add Comment | |
| Website CSS / Scribe | |
|---|---|
|
Date: 13/4/2023 Tags: website scribe | I've removed the fixed point sizes in this sites CSS so that the font size is free to adapt to the user's settings and screen DPI. Hopefully that'll improve the readability somewhat. I'm slowly working my way through a large backlog of Scribe UI testing. So that when I release v3.2 I'm reasonably sure that things aren't horribly broken. Because at this point, I'm finding that lots of things aren't working right. But at least now there is some visibility into my progress. |
| (1) Comment | Add Comment | |
| Scribe native export | |
|---|---|
|
Date: 8/3/2023 Tags: scribe | There has been a long running branch of Lgi and Scribe to remove the old synchronous way of doing dialogs as part of the work to re-enable Haiku support. And I decided the cost of keeping the branches separate was too high and merged all those changes into the main dev branch of those projects a few weeks back. This means that a bunch of old functionality that I haven't touched in a long time is now broken. For instance the Scribe mail3 export function. So I spent the last few days fully re-writing that to use the modern patterns and also optimize things a bit. Which has all been reasonably successful. It even has a nice new completion dialog: In that example I'd run it earlier and the replication had nothing to do. It's designed so you can use it to backup your folders and it's reasonably intelligent about replication of items. In terms of when there'll be a new release. There are a bunch more dark corners of Scribe that I never test, and they all need to be looked at. I'll keep working me way through them. |
| (1) Comment | Add Comment | |

| i.Disk on Haiku | |
|---|---|
|
Date: 20/2/2023 Tags: i.Disk | 
|
| (0) Comments | Add Comment | |
| Phabricator fork and the Scribe code base. | |||||||||
|---|---|---|---|---|---|---|---|---|---|
|
Date: 3/5/2022 Tags: scribe opensource | No one cares, but the announcement on 1st April wasn't a joke. Scribe is actually going open source. It's just taken way longer than I expected to create a new mercurial repository and have the hosting work correctly. Part of the issue is that my Phabricator install was misbehaving and it took a while to fix. I've had to create a fork of Phabricator and fix the passing of arguments to hg's web-server. I also had to clear out all the proprietary stuff in the Scribe code base, do some cleanup and get it all building again. Mostly that boils down to the OAUTH2 client secrets (good bye Gmail support) and the InScribe key checking code. That work is mostly complete now so I can publish the code base. It lives here: https://phab.mallen.id.au/source/scribeopensrc/ I'll be adding some more info on how to get it to build and updating the Scribe home page over the next few weeks. But it's slow going cause I have very little energy at the moment. I'm on day 14 since I got my first covid symptoms. Which have all cleared up bar the tiredness. Fortunately no one else in my family got it. Oh yeah, I've moved the versioning for the open source tree to "v3.x.x" just to make it clear where the new builds come from. The v2.4.22 changes will be rolled into a v3.0.0 build soon. As I won't make that build off the proprietary code base. Well ok, but how do you build it? hg clone https://phab.mallen.id.au/source/scribeopensrc/ code/scribe/trunk python code\scribe\trunk\build.py Should get you most of the way there. That currently just supports Windows but I will extend that support to other OS's as soon as I can. Requirements look like:
| ||||||||
| (2) Comments | Add Comment | |||||||||
| Scribe... | |
|---|---|
|
Date: 1/4/2022 Tags: scribe | ...is going open source. There will no free / paid versions. Just the full build available for free. Donate if you like. |
| (1) Comment | Add Comment | |